








Czym jest NLP?
NLP, czyli przetwarzanie języka naturalnego (ang. Natural Language Processing), to dziedzina informatyki i lingwistyki komputerowej zajmująca się analizą, interpretacją oraz generowaniem ludzkiego języka przez maszyny. Dziedzina przetwarzania języka naturalnego - NLP, umożliwia komputerom rozumienie i przetwarzanie tekstów oraz mowy w sposób zbliżony do ludzkiego. W tym artykule, używając skrótu „NLP”, odnosimy się jednak wyłącznie do tradycyjnych metod przetwarzania języka, stosowanych przed pojawieniem się dużych modeli językowych. Warto to podkreślić, gdyż NLP stanowi szeroką dziedzinę obejmującą zarówno klasyczne metody oparte na regułach i statystyce, jak i nowoczesne podejścia wykorzystujące uczenie głębokie. LLM są zatem jej integralną częścią – kolejnym etapem rozwoju przetwarzania języka naturalnego, a nie odrębną technologią. Klasyczne podejścia NLP bazują na regułach językowych, modelach statystycznych oraz ręcznie definiowanych cechach. Wykorzystują m.in. analizę składniową, tokenizację, modele n-gramowe czy klasyfikatory, takie jak Naive Bayes czy SVM, które są przykładami zastosowań uczenia maszynowego w NLP.
Czym jest LLM?
LLM, czyli Large Language Model, to zaawansowany model sztucznej inteligencji wyszkolony na ogromnych zbiorach danych tekstowych. W odróżnieniu od tradycyjnych metod NLP, LLM nie opiera się na regułach językowych czy ręcznie projektowanych cechach, lecz na głębokim uczeniu – głównie z wykorzystaniem architektury transformera i kluczowego mechanizmu uwagi. Dzięki temu potrafi analizować szeroki kontekst oraz przewidywać kolejne słowa w sekwencji tokenów, co pozwala na generowanie spójnych tekstów, udzielanie odpowiedzi na pytania, streszczanie dokumentów czy tłumaczenie języków z niespotykaną wcześniej skutecznością.
Modele takie jak GPT, BERT czy LLaMA to przykłady zaawansowanych algorytmów wykorzystujących wzorce językowe, które znajdują szerokie zastosowanie w generowaniu tekstu, analizie nastrojów, rozpoznawaniu mowy czy wsparciu wirtualnych asystentów. Ich działanie opiera się na danych szkoleniowych, które pozwalają im uczyć się zależności w długich sekwencjach tekstu. Pomimo licznych zalet, wyzwania LLM obejmują między innymi wymagania sprzętowe w trakcie treningu oraz ryzyko utrwalania błędów zawartych w danych treningowych.
W praktyce wykorzystanie wytrenowanych modeli LLM umożliwia automatyzację wielu zadań językowych w czasie rzeczywistym, otwierając nowe możliwości w dziedzinie przetwarzania języka naturalnego, takich jak retrieval augmented generation czy tworzenie bardziej naturalnych interakcji między ludźmi a maszynami.
Kluczowe różnice między NLP a LLM
Tradycyjne NLP i LLM różnią się zarówno podejściem technicznym, jak i zakresem możliwości. NLP w klasycznym wydaniu opiera się na ręcznie tworzonych regułach, analizie składniowej, prostych modelach statystycznych oraz dedykowanej inżynierii cech. Takie podejście wymagało specjalistycznej wiedzy lingwistycznej i było trudne do skalowania. LLM natomiast uczą się na ogromnych zbiorach danych bez potrzeby ręcznej ingerencji – same wykrywają zależności, kontekst i znaczenia w tekście. Kolejną różnicą jest uniwersalność – LLM są bardziej elastyczne i mogą być stosowane w różnych zadaniach bez konieczności projektowania odrębnych modułów. Również jakość wyników, zwłaszcza w kontekście, idiomach i niejednoznacznościach, zdecydowanie przemawia na korzyść LLM.
Wspólne wyzwania wobec NLP i LLM
Zarówno tradycyjne NLP, jak i LLM napotykają na podobne trudności, mimo różnic w podejściu. Jednym z głównych wyzwań jest stronniczość danych – modele uczą się na tekstach tworzonych przez ludzi, co może prowadzić do utrwalania uprzedzeń. Kolejnym problemem jest obsługa danych wrażliwych – w wielu zastosowaniach wymagane jest przestrzeganie zasad prywatności i bezpieczeństwa informacji. Trudność sprawia też rozpoznawanie intencji użytkownika, zwłaszcza w bardziej złożonych zapytaniach. Zarówno NLP, jak i LLM mogą również generować odpowiedzi pozornie poprawne, ale merytorycznie błędne. Pomimo postępów w uczeniu maszynowym i mechanizmach analizy danych wejściowych, skuteczność modeli wciąż zależy od jakości danych oraz kontekstu, w jakim są stosowane, a także od konkretnego zadania, które mają wykonać.
NLP i LLM w kontekście oszczędności
Zarówno tradycyjne NLP, jak i LLM mogą przyczyniać się do znaczących oszczędności – zarówno czasu, jak i zasobów. Klasyczne NLP sprawdza się w prostych, powtarzalnych zadaniach, takich jak filtrowanie spamu, rozpoznawanie nazw własnych czy analiza sentymentu, oferując niskie koszty obliczeniowe i łatwą integrację. LLM, mimo większych wymagań sprzętowych, mogą z kolei zastąpić wiele odrębnych modułów jednym wszechstronnym modelem, co upraszcza architekturę systemów i redukuje potrzebę rozbudowanej inżynierii. LLM pozwalają również automatyzować bardziej złożone procesy, jak generowanie treści czy obsługa klienta. W dłuższej perspektywie może to prowadzić do znacznego ograniczenia kosztów operacyjnych, zwłaszcza w dużych organizacjach.
Czy można korzystać z LLM bez NLP?
Trzymając się nomenklatury z naszego artykułu, LLM to coś innego niż tradycyjne metody NLP, jednak w pełnym znaczeniu tego terminu LLM są po prostu nowoczesnym etapem rozwoju NLP. Oznacza to, że choć technicznie można korzystać z dużych modeli językowych bez bezpośredniego stosowania klasycznych technik, całkowite pomijanie ich dorobku nie ma większego sensu. Tradycyjne metody, takie jak tokenizacja, analiza składniowa, rozpoznawanie bytów czy klasyfikacja tekstu, stanowią fundament, na którym opierają się współczesne modele. Co więcej, wiele systemów łączy podejścia klasyczne i LLM, tworząc rozwiązania hybrydowe – bardziej precyzyjne, szybsze lub tańsze w działaniu. Znajomość klasycznego NLP pozwala lepiej zrozumieć możliwości LLM i świadomie je wykorzystywać.
Tabela porównawcza - NLP vs LLM
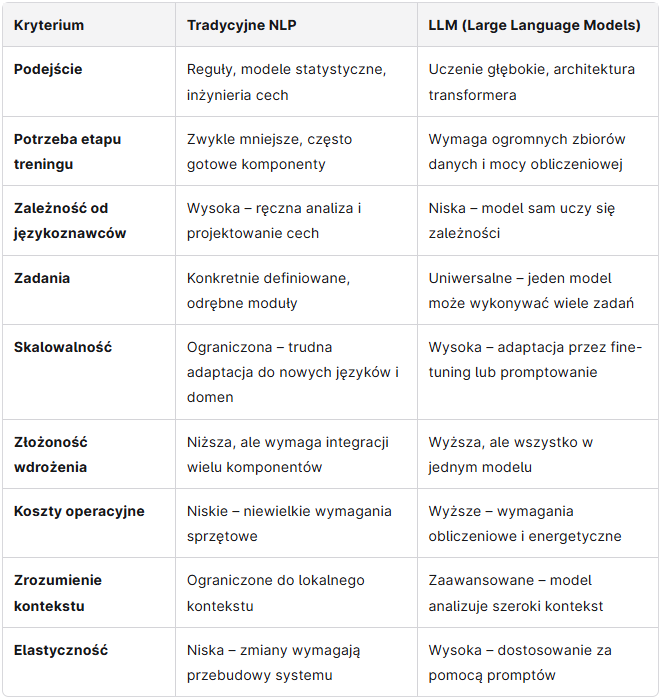
Kiedy stosować NLP, a kiedy LLM?
Wybór między tradycyjnym NLP a LLM zależy od skali projektu, dostępnych zasobów oraz złożoności zadania. Tradycyjne metody NLP świetnie sprawdzają się w prostych i powtarzalnych zastosowaniach, takich jak rozpoznawanie nazw własnych, ekstrakcja informacji, klasyfikacja wiadomości czy analiza sentymentu. Są lekkie, szybkie i tanie we wdrożeniu. Z kolei LLM warto stosować, gdy potrzebna jest głębsza analiza kontekstu, wielozadaniowość lub generowanie naturalnego języka – np. w chatbotach, automatycznym podsumowywaniu treści, tłumaczeniu czy tworzeniu dokumentów. LLM mogą też być lepszym wyborem tam, gdzie trudno jest z góry przewidzieć wszystkie możliwe scenariusze użycia języka. W wielu przypadkach warto jednak rozważyć połączenie obu podejść dla najlepszych rezultatów.
Praktyczne zastosowania NLP i LLM
Tradycyjne NLP znajduje zastosowanie w wielu stabilnych i dobrze zdefiniowanych procesach. Przykłady to filtrowanie spamu, analiza sentymentu opinii klientów, ekstrakcja nazw własnych z tekstu (np. firm, lokalizacji), klasyfikacja dokumentów, rozpoznawanie języka czy automatyczne uzupełnianie metadanych. Są to zadania, w których reguły i statystyki działają szybko, skutecznie i niskim kosztem.
LLM z kolei otwierają nowe możliwości dzięki rozumieniu kontekstu i generowaniu języka. Wykorzystuje się je m.in. w chatbotach, asystentach głosowych, tłumaczeniu maszynowym, streszczaniu dokumentów, analizie umów prawnych, kodowaniu, tworzeniu treści marketingowych czy wsparciu w obsłudze klienta. Modele te pozwalają automatyzować bardziej złożone zadania, które wcześniej wymagały ludzkiej interwencji lub wielu osobnych narzędzi.
Chcesz wykorzystać potencjał generowania języka naturalnego w swoim biznesie? Skontaktuj się z nami i odkryj, jak nowoczesne rozwiązania z zakresu sztucznej inteligencji mogą usprawnić Twoje procesy oraz pomóc zwiększyć efektywność!
Chcesz porozmawiać o projekcie IT?
Napisz do nas

.png)
.png)